
AI is increasingly a front door for surfacing general knowledge, but our team finds general-purpose AI assistants struggle to retrieve accurate information grounded in specific data, even when pointed to the right sources. We set out to test whether careful curation, preprocessing, and strategic work with experts could change that.
Our team has written about how retrieval-augmented generation (RAG) could provide AI tools with the context needed to ground responses, but when we piloted RAG frameworks, we were disappointed in the initial results. However, with some additional preparation and assistance from expert collaborators, we found we could meaningfully improve our knowledge base of text resources. Specifically, we found that, with some iteration, four preparatory steps paid major dividends.
This article describes how we built an AI-ready knowledge base for Urban’s Upward Mobility Initiative (UMI), which has produced technical assistance, data, and tools that have supported more than 120 communities since early work began in 2016. By grounding AI tools in this upward mobility context, we wanted to help prospective users navigate the sometimes-dizzying amount of information.
Our Setup
Step 1: Curating a knowledge base
Rather than dumping an entire universe of text about one topic into a knowledge base, we worked with Urban’s experts to curate a set of realistic questions users might ask of our resources. Questions ranged from short and concrete (“What are all of the upward mobility predictors?”) to open-ended and complex (“What are the promising local interventions for jobs paying a living wage, and what have the effects been of these initiatives?”).
We then selected about 280 documents best suited to answering those questions. These included foundational resources like Urban’s Toolkit for Increasing Upward Mobility, a set of web pages detailing the 24 predictors associated with long-term economic success.
These documents were assembled by dozens of experts to provide strategic guidance on upward mobility planning, identify mobility predictors to inform data-driven decisionmaking, and highlight promising local interventions.
Step 2: Preprocessing, or making knowledge AI ready
Most of the documents we collected lived in PDFs or in HTML, both of which had to be converted to machine-readable formats to be “AI ready.” Domain experts helped us collect and catalog key documents, and where web scraping was infeasible, saved PDF downloads in a centralized location.
We relied on open-source Python packages to convert the documents: docling for PDF-to-Markdown conversion and trafilatura for web scraping and HTML-to-Markdown conversion. Markdown was our preferred choice because of its token-efficient format that retains text and structural elements like headers and paragraphs.
We also decided to programmatically split longer documents by chapters or sections to ensure each encoded document was organized by topic and semantically coherent. Doing so manually wouldn’t be feasible or efficient at scale, but we found that automatically splitting targeted documents improved retrieval for the type of long document (e.g., a zoning code) our RAG struggled with in previous research.
Step 3: Tagging metadata to add crucial information
For every document, we included a .metadata.json file with key information to help AI tools parse and interpret documents. This file included multiple kinds of metadata, for example:
- General tags: Name, URL, source, publication year
- Context-specific tags: Document type (e.g., summary, evidence, local intervention), upward mobility pillar, relevant predictor
Many tags could be automatically extracted and applied through our collection and preprocessing. We also asked our experts to create higher-impact tags, such as how the model should interpret each document type.
Step 4: Building the infrastructure with AWS
After this setup, we had a knowledge base of valuable text about upward mobility, but no infrastructure or tooling to use it. We used Amazon Web Services (AWS) infrastructure throughout this pilot, with Amazon Bedrock Knowledge Bases as our main service for testing the feasibility of navigating our amassed knowledge. This service brings together the moving pieces necessary to build a successful RAG pipeline, which you can see in the architecture diagram below.
Figure 1: AWS Architecture Diagram
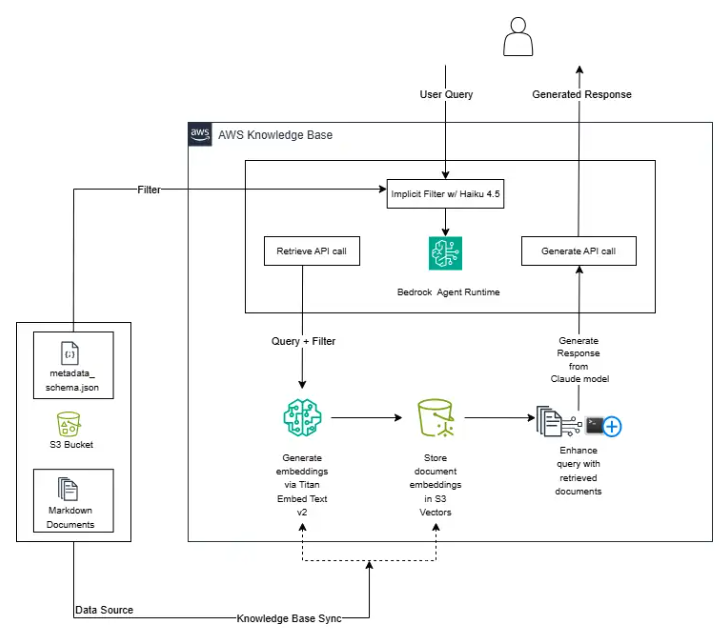
Throughout this process, we made judgment calls around technical decisions:
- We stored retrieval-ready (i.e., embedded) text in S3 Vector storage—a newer, more lightweight option, but with restricted functionality.
- We orchestrated our pipeline to include a detailed system prompt, which is an underlying set of instructions appended to every question to guide the large language model (LLM) toward desired responses and outcomes. In our prompt, we outlined the AI model’s role, desired tone, style, structure, requirements around careful citation, and exemplary responses (known as “few-shot prompting”).
- We used two LLMs to generate final responses: Simpler question types were routed to Claude Haiku 4.5, and more complex questions were handled by Claude Sonnet 4.6.
What We Learned
Much of the work to build AI that reliably interacts with our knowledge base depends on institutional, not technical, knowledge, and it had to be shaped by those closest to that work.
Building a useful knowledge base, even from a limited set of trusted sources, requires substantial upfront investment from a variety of stakeholders. Choosing representative questions, collecting and cataloging data sources that can answer those questions, flagging edge cases and limitations, and informing system prompting are all crucial tasks led by research collaborators. This required trust and communication between those closest to the content and those building AI tools that interact with the content.
Our collaborators drafted illustrative questions meant to test a variety of AI capabilities categorized by Wang and colleagues (2025)—such as multihop reasoning and long-form Q&A. Their expertise in homing in on the right questions was the first step toward figuring out how to construct the infrastructure to answer them.
Our preprocessing and curation steps were far more important than the infrastructural decisions in building a useful knowledge base.
We observed closely as retrieval steadily improved with each preprocessing decision. Splitting documents, adding and refining metadata tags, culling outdated or redundant text, and other work around the edges all made notable differences. Although we took these steps manually during the pilot phase, the learnings have allowed us to create programmatic pipelines to scale them more efficiently.
For example, we tried using intelligent metadata filtering, where a separate LLM filters the universe of relevant documents based on metadata tags. In theory, the model could answer a question about minimum wage by filtering to documents tagged with Predictor = “Jobs Paying a Living Wage”. In practice, filtering did not work well because of overly restrictive conditions (e.g., matches had to be exact and were case-sensitive), so the LLM removed relevant documents from consideration with no benefit.
To solve this issue, we focused on adding text descriptions to our metadata schema and to our system prompt:
Loading...
This change had two noticeable benefits. Relevant documents were not filtered out at the retrieval stage, and the LLM improved its use and characterization of these documents in its responses (e.g., by citing a document tagged with “Local Intervention” in a question about exemplary policy changes).
Using managed infrastructure can be more efficient, simpler, and more cost-effective, but it sacrifices some control.
AWS documentation answered many of our questions on setup, but certain algorithmic decisions made by AWS Bedrock are opaque. One such example: When retrieving relevant text to support a user’s query, the scoring methodology assigned to each snippet of text in a Bedrock Knowledge Base is a black box. This made it more difficult to know how curation and preprocessing steps could improve retrieval.
We could intuit that Bedrock used some kind of text similarity score to return the most relevant text, and these scores largely aligned with our expectations. While transparency is important for rigorous, careful piloting, we were willing to make these kinds of minor sacrifices to learn and work more efficiently.
Looking Ahead
Many research organizations like Urban are undoubtedly sitting on valuable institutional knowledge that users cannot easily navigate or synthesize. Our experience suggests that generative AI tools can offer a solution to that problem, but doing so requires well-crafted problem statements, careful preparatory work and trust building, and deep institutional expertise. As the technical barriers to entry continue falling, we no longer see access to better models and infrastructure as the core roadblocks.