
To effectively analyze a policy, researchers consider how it affects not only the overall population but also specific racial and ethnic groups. That’s because long-standing systemic barriers can lead to different outcomes for different groups.
For example, a tax deduction for first-time homebuyers—a policy intended to increase access to homeownership—can unintentionally widen racial homeownership gaps, because of differences in access to wealth (inherited or otherwise) needed to make a down payment on a home.
But race and ethnicity data are often missing, incomplete, or incorrect, making it difficult to disaggregate data.
In previous research, we found that in Pennsylvania, people of color were overrepresented in the criminal and eviction records captured in tenant screening reports, or databases landlords use to make leasing decisions. But because of incomplete race and ethnicity data, we were unable to easily isolate how tenant screening affected specific groups’ access to rental housing.
In a forthcoming data tool, we use imputation to fill in the missing values for race and ethnicity in those records. Typically, it is difficult to measure the quality of imputation results. For this analysis, however, we had the rare opportunity to validate our results against a complete dataset. We used a small set of criminal records that had complete race and ethnicity data to validate our imputation of race and ethnicity on criminal and landlord-tenant records that only had partial data available.
This imputation could help us explore the potential effects that fair chance housing and clean slate laws—laws that seal or limit access to criminal and eviction records—have on renters applying for housing. Before determining whether to publish these disaggregated findings, we will assess whether our results are sufficiently accurate and consistent with previous literature on rental, criminal, and eviction records in Pennsylvania.
In this post, we describe our approach, discuss which imputation methods worked well and the limits of imputation, and offer key considerations researchers should keep in mind when imputing race and ethnicity.
Data
For this analysis, we purchased criminal and landlord-tenant case record data from the Administrative Office of Pennsylvania Courts (AOPC).
We made two requests, one just before, and one just after Pennsylvania enacted its Clean Slate 3.0 law in February 2024, which reduced barriers to sealing certain criminal records. The first set of criminal records we received, pre-sealing, was much larger than the second, but it inadvertently omitted defendants’ ethnicity, so we specifically asked for ethnicity data in our second request.
As a result of our two requests, we had the following data:
- A small set of criminal records requested after Clean Slate 3.0 was enacted, with complete race and ethnicity data, which would serve as the “ground truth” against which to validate our imputation.
- A large set of criminal records requested before Clean Slate 3.0 was enacted, with race but not ethnicity data, for which we needed to impute only
- A large set of landlord-tenant records requested before Clean Slate 3.0 was enacted, with mostly missing race and ethnicity data, for which we needed to impute both race and ethnicity.
Because one dataset included complete race and ethnicity data, we could validate our racial imputation results for the other datasets against that ground truth.
Testing Imputation Methods
We tested the following imputation:
Though we assign a predicted race and ethnicity based on the highest probability when trying to assess the best-performing model, we use the imputed probabilities directly in our downstream analysis. Using imputed probabilities is the established best practice because it increases accuracy and reduces statistical bias.
Validating imputation Methods
To validate each method, we looked at the following outcome:

For example, a high-sensitivity model for Black renters would correctly impute the race of most Black renters as “Black,” while a high-specificity model would correctly avoid imputing the race of non-Black renters as “Black.”
Ultimately, we found that fBISG and BIRDiE with measurement error were not as effective at predicting racial probabilities as the base versions of BISG and BIRDiE. The validation results of BISG and BIRDiE were almost identical, so we chose the simpler model, BISG.
Interpreting BISG’s Results
Though BISG was the most reliable, its ability to correctly predict person-level race and ethnicity still had significant limitations.
Calibration
In a well-calibrated model, the y-axis values would fall within the range of each range listed on the x-axis. Though BISG wasn’t perfectly calibrated for any group, its predicted probabilities for Hispanic sample members were closest to our ground truth dataset.
BISG Is Best at Predicting the Proportion of the Population That Is Asian, Hispanic, or White
Predicted proportion of population versus true proportion, by race
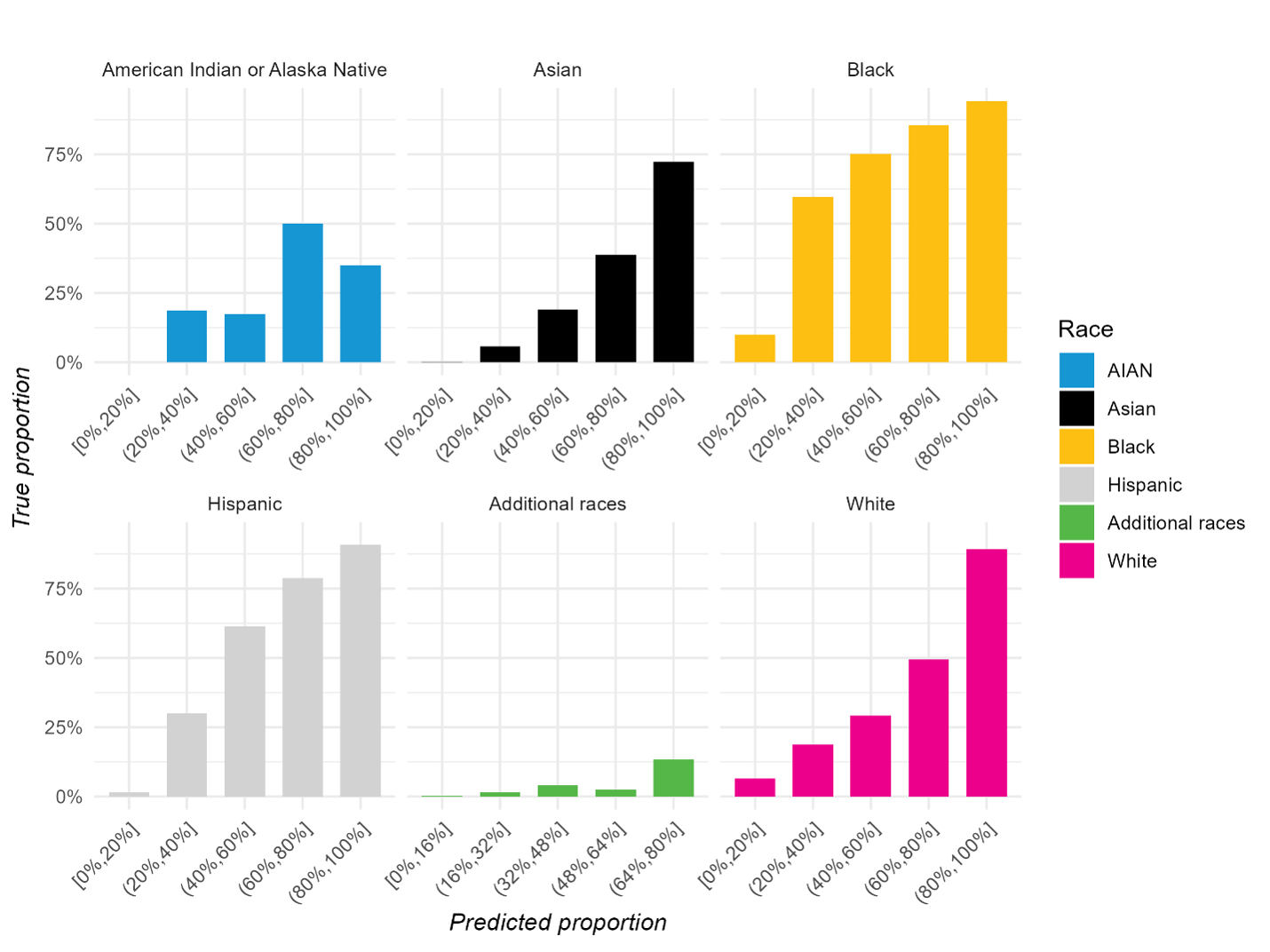
Note: Proportions are expressed as percentages. AIAN category includes American Indian or Alaska Native defendants, and the Asian category includes both non-Hispanic Asian and Native Hawaiian or other Pacific Islander defendants.
For example, where the x-axis shows a 20 to 40 percent predicted probability of being Hispanic, the true proportion is 25 percent on the y-axis. By comparison, the model under-identifies Black individuals and over-identifies white individuals.
Sensitivity and Specificity
The model has high sensitivity for Hispanic and white groups, moderate sensitivity for Asian groups, and low sensitivity for Black, American Indian or Alaska Native, and additional races.
Conversely, the model’s specificity is high for Black, Asian, American Indian or Alaska Native, Hispanic, and additional races. It often over-assigns non-white people to the white category, making specificity for this group lower.
BISG Struggled to Positively Identify the Share of Black People in the Sample
Sensitivity and specificity of the BISG model, by race and ethnicity
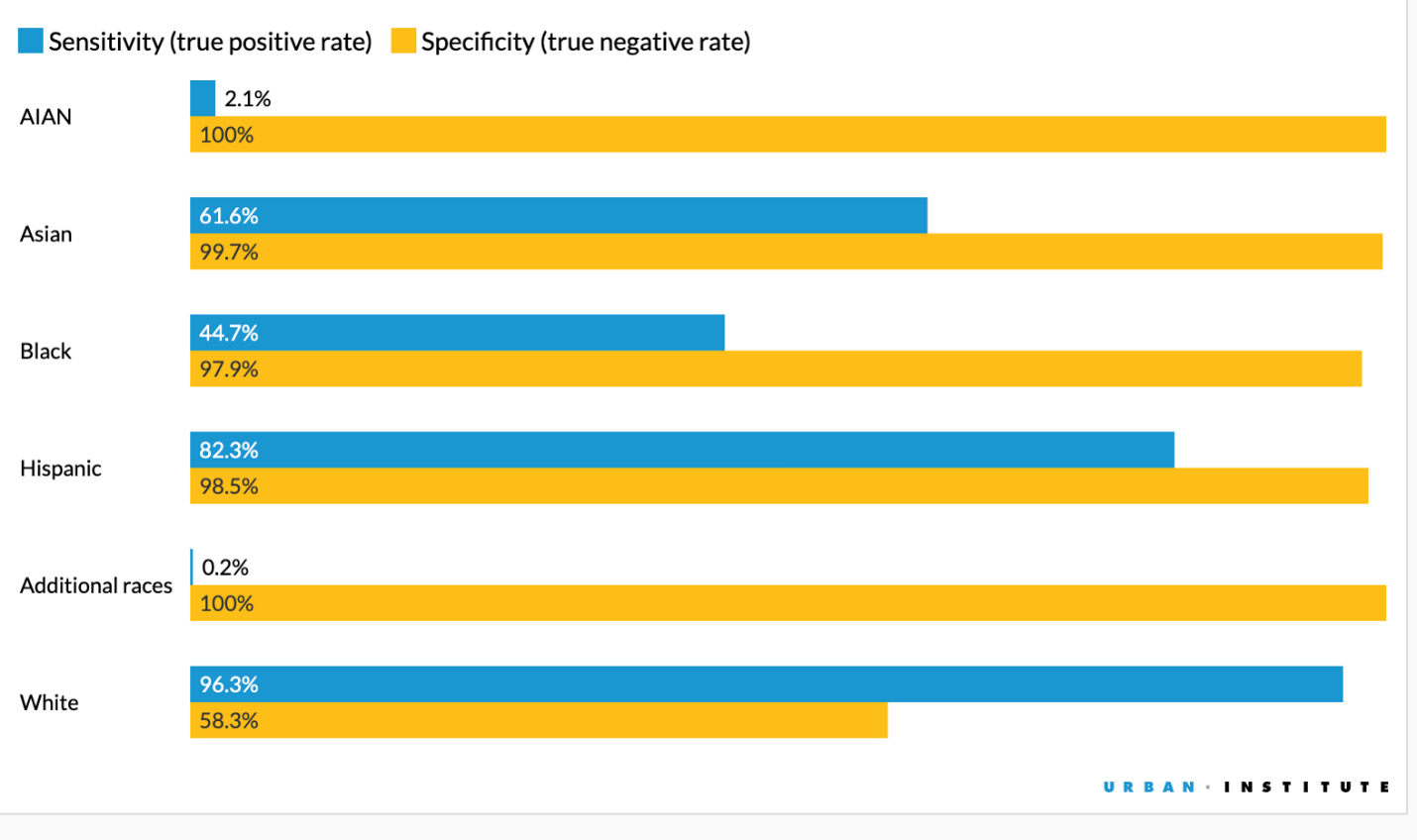
Note: Proportions are expressed as percentages. The AIAN category includes American Indian or Alaska Native defendants, and the Asian category includes non-Hispanic Asian and Native Hawaiian or other Pacific Islander defendants.
These validation results demonstrate the importance of considering the weaknesses and strengths of any model. BISG had high specificity for most groups, but this is partly because it has a bias toward identifying sample members as white, meaning other groups (Asian, Black, Hispanic, AIAN, and additional races) are consistently under-identified.
Converting to a Combined Race and Ethnicity Category
Imputation methods assume there’s a combined race and ethnicity field that includes the following categories:
- Non-Hispanic American Indian or Alaska Native (AIAN)
- Non-Hispanic Asian, Native Hawaiian, or Pacific Islander
- Non-Hispanic Black
- Non-Hispanic white
- Non-Hispanic multiracial and additional races
- Hispanic, any race
All of our datasets had separate race and ethnicity fields, meaning information on Hispanic or non-Hispanic identity was contained in a separate column. This meant that for the large set of criminal records that only included race, we needed to first impute the missing ethnicity values.
Because these Bayesian imputation methods rely on conditional likelihood, we used Bayes’ theorem to implement a creative work-around.
For the criminal records that have race but no ethnicity, we used each imputation model’s Pr(Hispanic) as the imputed ethnicity value. Then, for eviction records missing both race and ethnicity fields, we used Pr(Hispanic) as the imputed ethnicity value.
For each race, we used Bayes’ theorem, as follows:
Pr(Black) = Pr(Black | Non-Hispanic) * Pr(Non-Hispanic) +
Pr(Black | Hispanic) * Pr(Hispanic)
Pr(Black | Non-Hispanic) * Pr(Non-Hispanic) is equivalent to Pr(Non-Hispanic Black), which is one of the categories returned by each imputation model. We also derived Pr(Hispanic) from each imputation model, whereas we pulled Pr(Black | Hispanic) from American Community Survey data for each renter’s zip code.
With this final statistical adjustment, we were able to convert the combined race and ethnicity field returned by each model to separate fields that fit how AOPC collects race and ethnicity.
Key Considerations When Imputing Race and Ethnicity
To better understand our findings and how they might be useful, we consulted with technical practitioners and researchers who study racial equity. They raised several questions about our study that may be helpful for other researchers doing racial imputation. Those questions and our preliminary answers (as we finalize the data tool associated with this research) are presented below.
Where do the data come from?
We asked AOPC but did not receive a definitive answer about how race and ethnicity were collected. Because race and ethnicity are typically observed rather than self-reported in the criminal legal system, our best guess is that this information was likely observed (PDF) by court and law enforcement officers, rather than self-reported. Research shows that observed race and ethnicity data often undercount Hispanic, Asian, and AIAN defendants. This could introduce another source of measurement error into our validation process.
Because our analysis is pertinent to communities that are often undercounted in racial imputation, it is important to our team to not rely too conclusively on any estimated effects of fair chance laws on these smaller groups.
Who are you consulting before implementing an imputation method?
Unfortunately, the scope of our project did not allow us to reach out directly to Pennsylvanians with criminal or eviction histories to better understand whether any groups could be negatively affected by our research results. We had multiple discussions with experts in Urban’s Center for Equity and Community Impact to think through the risks and benefits of imputation for marginalized communities. We’re considering whether we will publish the final results of the racial imputation as part of our tool, and under what circumstances the benefits would outweigh potential harms.
In the future, we hope to engage with those most affected by tenant screening and understand their primary challenges accessing rental housing. Positioning those with lived experience as leaders and experts can amplify research’s impacts. For example, collaborating with renters to codesign and lead an data interactive and implementing changes to the tool based on community feedback could help us tailor this resource to those most affected by bias in tenant screening.
Why might your imputation results differ across racial and ethnic groups?
Several factors could explain why BISG performed differently across groups. Latino people tend to have less surname diversity, for instance, which can make them more easily identifiable for the model. Conversely, the surname and location indicators used in our model can be especially poor for smaller groups such as AIAN defendants.
Why are you imputing race and ethnicity, and how will your results be interpreted?
We found that BISG tends to under-identify Black and Asian defendants in our data, but people of color are overrepresented in the criminal legal system. Before deciding whether to publish our imputation results, we need to consider how the bias in our model may affect the conclusions people draw on any race-disaggregated data presented in our tool and any unintended consequences that could result.
Imputation is not a perfect fix for fundamental data and measurement problems, and the stories it can help tell are often quantitatively and qualitatively incomplete. Still, this exercise deepened our team’s understanding of how crucial context on renters with criminal and eviction records is for effectively evaluating policies that protect their access to housing.